object detection에 대한 개념 정리 및 해당하는 딥러닝 논문들을 소개한 글입니다.
최근 object detection에 관련해 계속 공부하고 있었는데, 한번 방법 별로 논문들을 정리해보면 좋을 것 같아서 글을 작성하게 되었습니다 :)
Object Detection 이란?
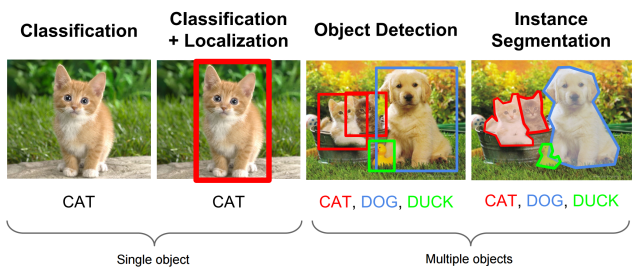
object detection은 classification + localization 으로 여러가지 object에 대한 classification과 그 object들의 위치정보를 파악하는 것을 동시에 하는 분야입니다.

의료장비, 자율주행자동차, 대형마트 등 활용되는 영역이 매우 넓고, 연구도 매우 활발히 되는 분야입니다. 위 그림만 봐도 굉장히 다양한 논문들이 나오고 있는 것을 볼 수 있습니다.
일반적으로 object detection의 딥러닝 네트워크는 2-Stage Detector 와 1-Stage Detector 로 구분하고 있습니다. 간단히 말하면, localization과 classification이 따로 이루어지면 2-Stage Detector, 동시에 이루어지는 것이 1-Stage Detector 입니다. 2-Stage에서는 먼저 object가 있을거라고 생각하는 영역을 뽑아주고 그 영역 각각에 대해 classification을 해줍니다. 1-Stage에서는 이 과정이 동시에 이루어지기 때문에 더욱 속도가 빠른 장점이 있습니다. (자세한 내용은 제이스핀님 블로그 참고)

2-Stage와 1-Stage 방법의 대표적인 논문들을 직접 정리해보았습니다. 원래 2-Stage와 1-Stage 사이에서 2-Stage는 정확도가 높지만 느리고 1-Stage는 빠르지만 2-Stage보다는 정확도가 낮다는 것으로 구분이 되었는데, 최근에는 1-Stage 방법들이 2-Stage의 정확도를 따라잡으면서 그러한 구분이 약간은 무의미해진 것 같습니다.
그래서 저는 추가로 1-Stage 방법에서도 anchor-based 와 non anchor-based로 구분해보았습니다. 단순히 두 단계인지 한 단계인지의 구분보다는 anchor를 이용하는지 anchor를 이용하지 않는지의 차이가 더 큰 것 같아서 이렇게도 구분을 해보았습니다.
그럼 위 그림에서 대표적인 논문들 (Faster R-CNN, YOLO, SSD, CornerNet, CenterNet)을 간단하게 컨셉 위주로 정리해보도록 하겠습니다.
Faster R-CNN

Faster R-CNN은 2015년도 NIPS 논문에서 소개되었던 모델입니다. 기존에 Fast R-CNN 구조에 RPN(Region Proposal Network)을 추가하였습니다.
우선 일반 이미지에서 convolution layer들을 적용하여 feature map을 뽑아낸 다음, 여기서 object가 있을 것 같은 영역 (RoI)를 뽑아주고 해당 영역들을 RoI Pooling을 통해 사이즈를 통일시킨 뒤, 각각 영역들을 classifier를 통해 최종 이미지 라벨과 bounding box를 추출합니다.
여기서 RoI를 R-CNN이나 Fast R-CNN에서는 selective search를 이용해 추출했었다면 (딥러닝 아닌 방식), 이 모델에서는 RPN 딥러닝 네트워크를 이용하여 end-to-end learning을 가능하게 했습니다. RPN에서는 위에 오른쪽 그림과 같이 feature map에 sliding window를 적용시켜 각 window마다 k개의 anchor box들을 이용해 그 영역에 object가 있는지/없는지 스코어와 4개의 좌표를 뽑아냅니다. 그 다음, 이 영역들에 classifier를 적용합니다.
Faster R-CNN을 포함한 2-Stage 방법들 (Fast, Faster, Mask R-CNN)의 자세한 설명은 Lil’Log 글을 참고바랍니다.
이 논문은 RPN을 적용하여 이전 Fast R-CNN 보다는 빨라졌지만, feature map의 각 영역마다 k개의 anchor box가 생성되기 때문에 속도가 여전히 매우 느립니다.
YOLO
YOLO는 2-Stage object detection 모델들의 느리다는 단점을 해결한 최초의 real-time object detector 입니다. 2016년 CVPR에서 발표된 논문입니다.
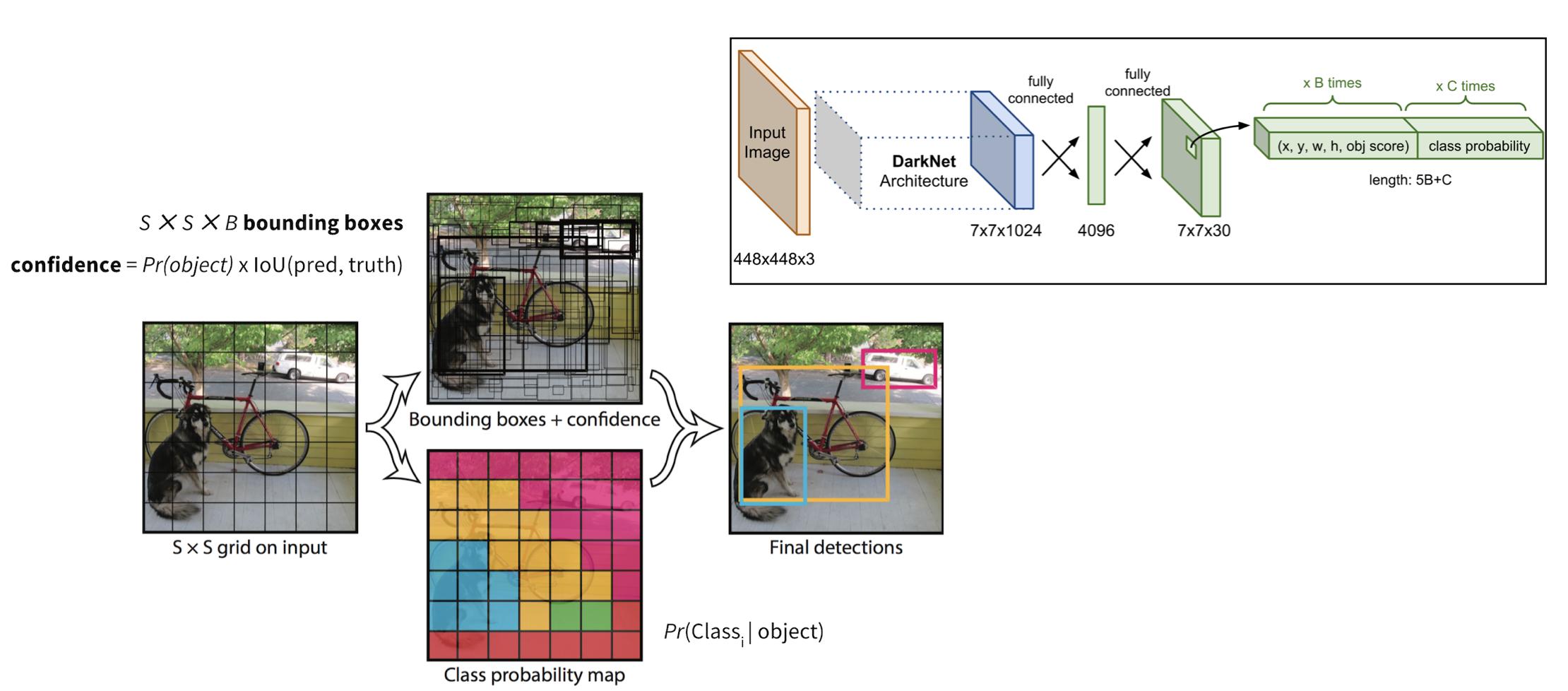
여기서는 convolution layer들을 통해 feature map을 추출하고, fully connected layer를 거쳐 바로 bounding box와 class probability를 예측합니다. YOLO에서는 input 이미지를 SxS grid로 나누고 각 grid 영역에 해당하는 bounding box와 confidence, class probability map을 구했습니다. 이때, 한 grid 영역당 5개의 bounding box coordinate와 confidence score를 구하였습니다.
이 YOLO 논문에 이어서 더욱 성능을 향상시킨 YOLO v2, 다양한 클래스로 확장시킨 YOLO9000 등의 모델들이 나오게 되었습니다.
SSD
YOLO와 같은 1-Stage object detection 입니다. YOLO에서는 이미지를 grid로 나누어서 각 영역에 대해 bounding box를 예측했다면, SSD 는 CNN pyramidal feature hierarchy 를 이용해 예측합니다. SSD는 2016년 ECCV에서 발표된 논문입니다.

이미지에서 보여지는 object들의 크기는 매우 다양하고 convolution layer 들을 통해 추출한 한 feature map만 갖고 detect 하기에는 부족하다라는 생각에서 나온 논문입니다. SSD에서는 image feature를 다양한 위치의 layer들에서 추출하여 detector와 classifier를 적용합니다. 앞쪽 layer에서는 receptive field size가 작으니 더 작은 영역을 detect 할 수 있고, 뒤쪽 layer로 갈수록 receptive field size가 커지므로 더 큰 영역을 detect 할 수 있다는 특징을 이용했습니다.
SSD는 YOLO 보다 속도나 정확도 측면에서 더 높은 성능을 보였고, 이어서 DSSD, RetinaNet 등의 논문이 발표되었습니다.
YOLO와 SSD 등과 같은 anchor based의 1-stage detector들에 대한 더 자세한 설명은 Lil’Log 글을 참고해주세요.
CornerNet
CornerNet 은 2018년도 ECCV에서 발표된 논문입니다. 기존 object detection 방법들은 모두 anchor box를 이용하여 detect 하였습니다. 하지만, 이미지에 1~2개의 물체를 detect 하기위해 수백 수천개의 anchor box를 사용하는 것은 너무 낭비이고(huge imbalance), 어떤 모양의 anchor box를 사용할 것인가(hyperparameter setting)도 큰 문제였습니다. 이 논문에서는 pair of keypoints 로 물체를 detect 합니다.
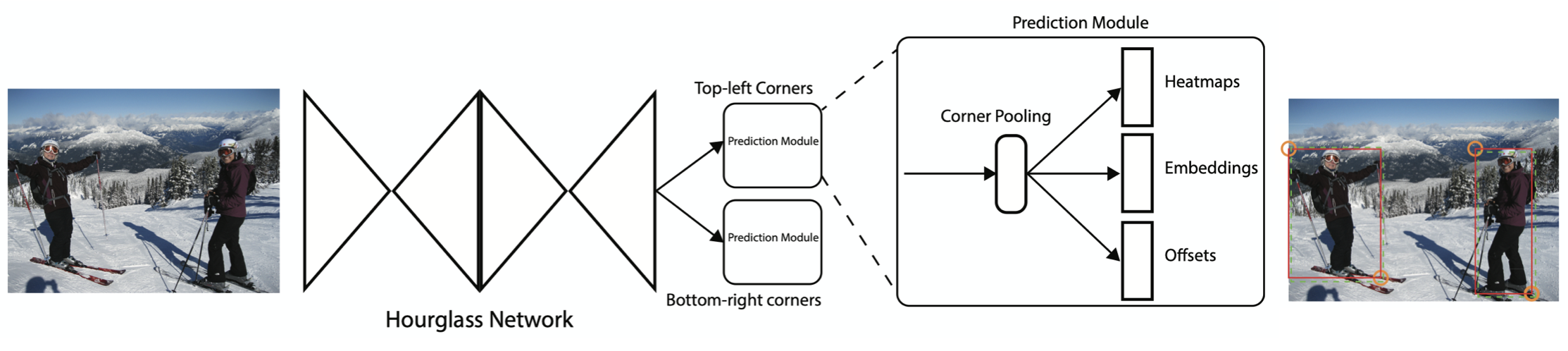
이 모델에서는 human pose estimation에서 많이 쓰이는 hourglass network를 backbone으로 합니다. hourglass 네트워크를 통해 두 개의 포인트 (object의 왼쪽위 포인트, 오른쪽 아래 포인트)에 해당하는 값을 얻고, Prediction module을 통해 그 위치의 heatmap, 같은 물체인지 파악할 수 있는 embedding, 정확한 bounding box 위치 파악을 위한 offset을 얻고 이것들을 이용해 object detect를 합니다.
구체적으로 적용한 방법으로는 RetinaNet의 focal loss를 적용하였고, corner pooling을 통해 더 정확한 bounding box를 얻게 하였고, associative embedding을 이용해 corner를 grouping 해준 것들이 있습니다.
object detection을 할 때 최초로 anchor box를 사용하지 않고 point estimation을 했다는 점에서 인상깊은 논문이고, 기존 논문들과 비교해도 더 좋은 성능을 보였습니다.
CenterNet
CenterNet 은 2019년도에 나온 논문으로 CornerNet이 2개의 점을 추출하였다면, CenterNet은 오직 single point로 object를 detect 합니다.

위 그림과 같이 한 점 (center point)과 물체의 사이즈, offset을 output으로 하여 예측하고 대략적인 구조는 CornerNet과 비슷합니다. 다만, CenterNet에서는 CornerNet 과 같이 hourglass 만 backbone으로 사용하는 것이 아닌 ResNet, DenseNet, DLA 역시 backbone으로 사용하여 실험을 하였습니다. 또한, object detection 뿐만 아니라 3D detection, pose estimation에서도 활용되었고 속도면에서 높은 성능을 보이기도 하였습니다.
object detection의 전체적인 흐름과 제가 중요하다고 생각하는 논문들을 소개해보았습니다. 아무래도 non anchor-based 방법들이 간단하기도 하고, 개인적으로 발전시키면 더 잘 될것 같다는 생각이 들어서 마음에 드는 것 같습니다.
Reference:
[1] Faster R-CNN 논문
[2] YOLO 논문
[3] SSD 논문
[4] CornerNet 논문
[5] CenterNet 논문
[6] 제이스핀님 블로그
[7] Lil’Log
[8] Lunit Tech Blog
'AI > 딥러닝' 카테고리의 다른 글
| Deep Learning(ANN, DNN, CNN, RNN, SLP, MLP) 비교 (0) | 2021.06.30 |
|---|---|
| 물체 감지 : 속도 및 정확도 비교 (더 빠른 R-CNN, R-FCN, SSD, FPN, RetinaNet 및 YOLOv3) (0) | 2021.06.28 |
| CNN: Single-label to Multi-label (0) | 2021.06.04 |
| [Object Detection] Darknet 학습 준비하기 (0) | 2021.06.04 |
| DataSet, DataTable이란? (0) | 2021.06.04 |



댓글