오늘은 머신 러닝(Machine Learning)의 개념과 기본적인 원리에 대해서 설명드리겠습니다.
인공지능을 구현하기 위해서 빼놓을 수 없는 기술중에 하나가 바로 머신 러닝.
즉, 기계 학습입니다.
머신 러닝 이란?
머신 러닝은 기계가 데이터로부터 스스로 학습하여 실행할 수 있는 알고리즘을 개발하는 분야를 말합니다.
머신 러닝과 데이터 마이닝(Data Mining)은 얼핏 들어보면 같은 얘기를 하는 것처럼 들릴 때가 있습니다.
대부분의 내용은 비슷하지만 차이점이 있습니다.
데이터 마이닝은 데이터 안에서 알려지지 않은 속성을 찾는 것이 주 목적인 반면에
머신 러닝의 주 목적은 데이터의 알려진 속성들을 학습하여 예측 모델을 만드는 데 있습니다.
데이터 마이닝 뿐만 아니라 컴퓨터 과학(Computer Science)나 통계학(Statistics)에서도 비슷한 개념들을 다룹니다.
그도 그럴 것이 머신 러닝이라는 분야가 이 세 가지 학문 분야에 모두 걸쳐있기 때문입니다. 아래 그림처럼요.
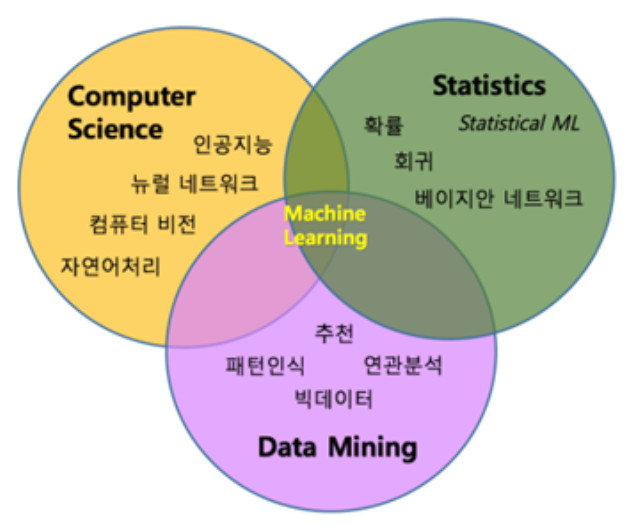
따라서 머신러닝은 컴퓨터 과학(Computer Science), 통계학(Statistics), 데이터 마이닝(Data Mining) 세 분야의 학문 모두에 속해있다고 볼 수 있습니다.
머신러닝 종류
머신러닝은 학습 방법에 따라 크게 세가지로 분류할 수 있습니다.
아래 그림처럼 지도 학습(Supervised Learning), 비지도 학습(Unsupervised Learning), 강화 학습(Reinforcement Learning)이 바로 그것입니다.

지도형 학습(Supervised Learning)
지도형 학습은 이미 정답을 알고 있는 데이터(Labled data)를 학습해서 새로운 데이터에 대해 결과를 예측하는 학습 방법을 말합니다.
아래 그림에서처럼 다양한 오리 이미지과 오리가 아닌 이미지들을 학습해서 모델을 만들고
이 모델을 활용해서 이전에 접해보지 못한 새로운 이미지가 오리인지 아닌지 예측하는 것이죠.

학습의 주 목적은 예측(Predict)이며 다양한 케이스의 데이터를 학습할 수록 적중률의 상승합니다.
대부분의 경우 학습 데이터가 많을 수록 성능도 좋아지는 경향이 있습니다.
알파고(AlphaGo)가 수많은 인간의 기보를 학습하여 승리하는 방법을 배운 것 처럼요.
주요 알고리즘은 회귀(Regression)와 분류(Classification) 입니다.
- Linear Regression
- Logistic Regression (Binary Classification)
- Multinomial Classification
- Decision Tree
- Random Forest
- KNN (K-Nearest Neighbors)
비지도형 학습(Unsuperviesed Learning)
비지도형 학습은 정답이 존재하지 않는 데이터들을 학습해서 데이터를 분류하는데 주 목적이 있습니다.
주로 군집화(Clustering)에 활용이 되는데요, 기존에 알지 못했던 새로운 특징을 추출하거나 서로 관련이 높은 그룹끼리 자동으로 분류할 수 있습니다.

예측이 주 목적이 아니다 보니 주로 지도형 학습을 진행하기 전에 전처리 하는 과정에서 많이 사용되는 학습법입니다.
주요 알고리즘은 아래와 같습니다.
- K-means
- Apriori
강화 학습(Reinforcement Learning)
강화 학습은 미리 학습 데이터를 준비할 필요가 없는 학습 방법입니다.
학습을 수행할 주체인 에이전트(Agent)를 생성하고 에이전트가 활동하게 될 환경(Environment)를 구성한 다음
에이전트의 행동(Action)을 관찰하여 적절한 보상(Reward)를 주는 방식으로 에이전트의 행동을 더 나은 방향으로 개선시키는 학습 방법입니다.
인간이 학습을 하는 것과 매우 유사하다고 볼 수 있습니다.

에이전트의 행동에 대해 좋지 못한 결과가 나오면 패널티를, 좋은 결과에 대해서는 적절한 보상을 주면서 행동 패턴을 점점 더 좋은 방향으로 개선시키면 데이터 없이도 학습을 시킬 수 있습니다.
실제로 고전 오락실 게임(아타리)을 강화 학습 이용해 학습한 결과 50여개의 게임 중 3~5개를 제외하고는 모두 강화 학습으로 학습한 AI가 사람보다 우수한 성적을 거두었습니다.
정말 놀라운 일이죠!
이전 포스팅에서 소개드렸던 알파고 제로(AlphaGo Zero)가 인간의 기보 없이 강화 학습을 이용해 학습한 버전입니다.
주요 알고리즘은 아래와 같습니다.
- Markov Decision Process
출처: https://gracefulprograming.tistory.com/103 [Peter의 우아한 프로그래밍]
'AI > 머신러닝' 카테고리의 다른 글
| [머신 러닝 :: 분류 문제] Multi-class VS. Multi-label 분류 문제 차이점은? (0) | 2021.06.04 |
|---|---|
| [Machine Learning] 머신러닝 개념 및 원리 - (1) 머신러닝 정의 및 지도학습, 비지도학습 차이 (0) | 2021.03.23 |


댓글