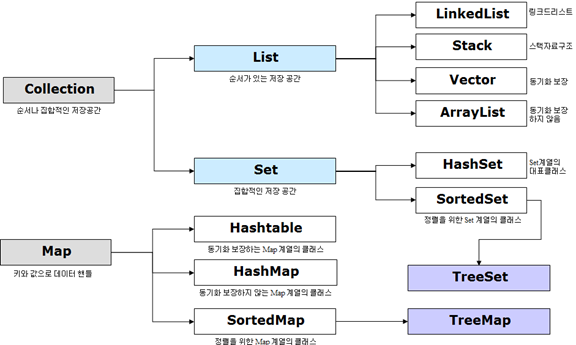
Java Collection Framework(JCF)
: Java에서 데이터를 저장하는 자료구조들을 한 곳에 모아 편리하게 관리하고 사용하기 위해 제공하는 것. 크게 List, Set, Map으로 구분할 수 있다.
이번 포스팅에서는 각각이 사용할 수 있는 메소드보다는 대략적인 큰 그림을 정리하기에 집중할 것이고 (메소드는 구글링만 해도 충분히 쉽게 찾아낼 수 있다. ), 몇개의 자료구조를 뽑아 설명해보겠다.
List 인터페이스와 Set 인터페이스를 설명하기 이전에 알고 넘어가야할 점은, 컬렉션은 기본 데이터형이 아닌, 참조 데이터형만 저장이 가능하다는 것이다. 따라서 Collection에서의 데이터는 Object 타입의 객체로서 저장이 되는 것인데, 그렇다면 여기서 기본 데이터형은 어떻게 저장하고 관리할 수 있을까?
기본 데이터 형은 Wrapper 클래스를 이용하여 Boxing 시켜주거나, (Integer num = new Integer(5); 와 같은 코드로 구현할 수 있다 : 기본 데이터형인 5를 Wrapper클래스의 Integer 타입 객체로 변환) autoboxing으로 저장할 수 있다. 즉, 오토박싱을 통해 기본 데이터형을 컬렉션에 직접 대입하여 저장해도 컴파일러가 자동으로 Wrapper 클래스로 변환해준다(collection.add(11); )
저장된 값을 얻어올 때에도 객체화된 데이터를 기본 데이터형으로 바로 얻어올 수 있는 데, 이 경우 언박싱(unboxing)이라는 용어를 사용한다.(collection.get(n); )
List : 인터페이스
- 동일한 데이터의 중복을 허용한다.
- 데이터 저장 순서가 유지된다.
- 힙(heap) 영역 내에서 List는 객체를 일렬로 늘어놓은 구조를 하고 있다.
- 객체를 인덱스로 관리하기 때문에 객체를 저장하면 자동으로 인덱스가 부여되고 인덱스로 객체를 검색, 삭제할 수 있다. 이 때 List 컬렉션은 객체 자체를 저장하여 인덱스를 부여하는 게 아니라, 해당하는 인덱스에 객체의 주소값을 참조하여 저장한다.
- List 컬렉션에서 공통적으로 사용가능한 추가, 검색, 삭제 메소드를 갖고있다.
Arraylist
Arraylist는 List 인터페이스의 구현 클래스로, 여기서의 객체는 인덱스로 관리된다. ArrayList에 객체를 추가하면 객체가 인덱스로 관리되는 것이다. 이 점은 일반 배열과 별 다를바 없지만, 자바에서 배열은 초기화 시 그 크기가 고정되어야하고 사용 중에 크기를 변경할 수 없다는 점에서 Arraylist는 가치가 있다. 설정하고 싶은 초기 용량이 n이라고 했을 때에는 아래와 같이 선언한다.
|
List<T> list = new Arraylist<T>(n); |
예를 들어 설명해보자.
import java.util.*;
public class Examples {
public static void main(String[] args){
int size;
List<String> list = new ArrayList<String>();
list.add("A");
list.add("B");
list.add("C");
list.add("D");
list.add("E");
list.add("F");
list.add("G");
list.add("H");
list.add("I");
list.add(1, "J");
size = list.size();
System.out.println("저장된 객체 수 : "+ size);
for(int i=0; i<size; i++){
//데이터를 인덱스로 관리
System.out.print(i + "번째 : " + list.get(i));
System.out.println();
}
System.out.println();
System.out.println("----------------변경 후----------------");
System.out.println();
list.remove(1);
list.remove(1);
size = list.size();
for(int i=0; i<size; i++){
System.out.print(i + "번째 : " + list.get(i));
System.out.println();
}
}
}
arraylist를 이용한 간단한 데이터 저장과 삭제를 구현해보았다.
List<String> list = new ArrayList<String>(); : 기본 생성자로 ArrayList 객체를 생성하면 내부에 10개의 객체를 저장할 수 있는 초기 용량을 가지게 된다. 만약 위 코드에서 list.add("more"); 로 1개의 객체를 추가하면, 즉 저장 용량을 초과한 객체들이 들어오면 list가 참조하고 있는 ArrayList 컬렉션에는 10*2+2 = 22개의 객체를 저장할 수 있는 공간이 자동으로 생겨난다. 하지만, 배열과 마찬가지로, 이 코드도 List<String> list = new ArrayList<String>(40); 처럼 용량을 초기화하여 원하는 만큼의 객체를 저장할 수 있다. 또한, ArrayList list = new Arraylist(); 로 참조변수를 생성하여 ArrayList를 사용할 수도 있다.
list.remove(1); : 이 코드를 두 번 실행하였으나 컴파일 도중 아무런 문제가 없었다. ArrayList는 중간에 위치한 객체를 삭제하여도, 그 인덱스를 자동으로 업데이트 해주기 때문에, 인덱스 1 이 처음 삭제된 후, 뒤의 객체들이 앞으로 한 칸씩 이동하며 그 자리를 자동으로 메꾸는 형태가 된다.
list.get(i) : 이렇게 얻어온 데이터를 바로 출력하는 것이 아니라, String 형의 변수에 다시 담는다고 생각해보자. 위에서도 언급했듯이, list.add(); 로 저장되는 모든 데이터는 Object 타입의 객체이다. 따라서, String 형 변수에 get해온 값을 담고 싶다면 String alphabet = (String)list.get(i) 와 같은 형변환을 반드시 해주어야 한다. 자신이 넣어준 데이터 타입으로 형변환해주는 것은 필수이다.
위에서 언급한 저장소의 용량 확장에는 ArrayList<E>의 단점이라 말할 수 있는 문제점이 있다.
바로, 저장소의 용량을 늘리는 과정에서 많은 시간이 소요된다는 점이다.
저장 공간 부족으로 ArrayList의 용량을 늘리게 되는 경우, 기존의 ArraList에 추가하는 것이 아닌, 확장된 크기의 ArrayList를 새로 생성하고, 그 새로 생성된 ArrayList에 기존의 ArrayList 값들을 복사해주는 과정을 거친다. 그리고 기존의 ArrayList는 가비지 컬렉션에 의해 메모리에서 제거된다. 따라서 ArrayList에서 용량을 늘린다는 것은 새로운 배열 인스턴스의 생성과 기존 데이터의 복사가 필요한 번거로운 작업이 되는 것이다.
위 코드의 이해를 추가적으로 돕기 위해, 결과물 출력 화면을 함께 올리겠다.

Vector
Vector는 Arraylist와 동일한 내부 구조를 가지고 있다. Vector를 생성하기 위해서는 지정할 객체 타입을 타입 파라미터로 표기하고 기본 생성자를 호출하면 된다.
|
List<E> list = new Vector<E>(); |
ArrayList와 다르게, Vector는 동기화된 메소드로 구성되어 있기 때문에 멀티 스레드가 동시에 이 메소드들을 실행할 수 없고, 하나의 스레드가 실행을 완료해야만 다른 스레드가 실행을 할 수 있다. 따라서 멀티 스레드 환경에서 안전하게 객체를 추가, 삭제할 수 있다.
객체를 추가하고 삭제하고 가져오는 메소드는 ArrayList 코드와 같기 때문에 Vector 예제를 따로 올리지 않겠다.
LinkedList
LinkedList는 List 구현 클래스이므로 ArrayList와 사용하는 메소드는 같지만 내부 구조는 완전 다르다. ArrayList는 내부 배열 객체를 저장해서 인덱스로 관리하지만, LinkedList는 양방향 포인터 구조로, 각각마다 인접하는 참조를 링크해서 체인처럼 관리한다.

따라서, LinkedList는 특정 인덱스의 객체를 제거하거나 삽입하면, 앞 뒤 링크만 변경되고 나머지 링크는 변경되지 않는다. 그러므로 중간 삽입/삭제가 빈번할 수록 LinkedList를 쓰는 것이 효율적이다. 반대로, 순차적인 삽입/삭제가 빈번하다면 ArrayList를 사용하는 것이 효율적이다.
LinkedList를 생성할 때, 처음에는 어떠한 링크도 만들어지지 않기 때문에 내부적으로 비어있다. 아래와 같은 코드로 생성할 수 있다.
|
List<E> list = new LinkedList<E>(); |
자바에서 LinkedList 클래스는 스택과 큐를 구현하는 데에 자주 쓰인다. 그 중 큐는 자바에서 일반적으로 두가지 방법으로 구현된다. 배열을 사용하여 구현하거나, LinkedList나 ArrayList 클래스를 사용하는 데, 지금은 LinkedList를 사용한 큐의 구현을 먼저 보이고, 다른 포스팅에서 배열을 사용하여 큐를 한 번 더 구현함으로서 찬찬히 뜯어보도록 하겠다.
LinkedList -> Queue 자료구조 구현
이 코드를 구현하면서 흥미로웠던 점은, List<E> list = new LinkedList<E>(); 로 선언을 권장했던 기존 자료구조 코드들와는 달리, 큐를 구현할 때 사용하는 메소드를 집어넣기 위해서는 반드시 LinkedList<E> list = new LinkedList<E>(); 라는 생성자를 사용해야한다는 점이였다. 그 말은 즉, offer(), poll(), peek() 와 같은 메소드가 List인터페이스에서 제공하지 않는, LinkedList클래스만의 메소드라는 말이 되겠다.
import java.util.*;
class QueueExample{
public void method(){
LinkedList<Integer> queue = new LinkedList<Integer>();
//Queue에 삽입
queue.offer(11);
queue.offer(22);
queue.offer(33);
queue.offer(44);
queue.offer(55);
System.out.println(queue);
System.out.println(queue.poll()); //Queue에서 맨 앞 요소 제거하며 읽기
System.out.println(queue);
System.out.println(queue.peek()); //Queue에서 제거하지 않고 맨 뒤 요소 읽기
System.out.println();
ListIterator<Integer> it = queue.listIterator();
if(it.hasNext()){
System.out.println(it.next());
System.out.println(it.next());
System.out.println(it.previous());
System.out.println(it.previous());
}
}
}
public class Sample {
public static void main(String[] args){
QueueExample ex = new QueueExample();
ex.method();
}
}
/*
----------------------------------print----------------------------------
[11, 22, 33, 44, 55]
11
[22, 33, 44, 55]
22
22
33
33
22
-------------------------------------------------------------------------
*/
Queue는 알다시피 FIFO, 선입선출 방식을 채택한다. 따라서 offer(); 메소드를 사용하여 Queue에 요소를 삽입하고 출력했을 땐, 들어간 순서대로 출력이 된다. 이 외에도 코드에서 보이듯 크게 두가지 메소드가 큐의 구현을 돕는다.
poll() : Queue에서 맨 처음 요소를 제거하며 출력
peek() : Queue에서 제거하지 않고 맨 뒤 요소를 출력
마지막 부분의 ListIterator는 Iterator의 기능을 포함하지만 좀 더 유용하게 쓰일 것 같아 삽입해보았다. 기존에 많이 활용하던 Iterator는 다음 데이터만을 검색할 수 있었고, dataset의 처음부터 끝까지 순차적으로 요소들을 검색하는 기능을 제공하였다.
하지만 ListIterator는 이전에 지나간 요소도 검색할 수 있는 기능을 포함하는 인터페이스이기 때문에, 코드에서 previous() 메소드를 활용하여 이를 구현하였다.
이처럼 스택에 대한 코드도 LinkedList클래스를 활용하여 구현할 수 있지만 큐와 사용하는 메소드만 다를 뿐 전반적인 흐름은 같으니 자세한 설명은 생략하겠다. 모두 알다시피 Stack 자료구조를 위해서는 push(), pop(), peek() 메소드를 활용하면 충분히 쉽게 구현할 수 있다.
Set : 인터페이스
- 데이터의 저장 순서를 유지하지 않는다.
- 같은 데이터의 중복 저장을 허용하지 않는다. 따라서 null도 하나의 null만 저장할 수 있다.
- Set 컬렉션은 List 컬렉션처럼 인덱스로 객체를 검색해서 가져오는 메소드가 없다. 대신 전체 객체를 대상으로 한 번 씩 다 가져오는 반복자, Iterator을 제공한다.
|
1 2 |
Set<String> setExample = new...; Iterator<String> iterator = setExample.iterator(); |
cs |
이 코드를 구현하여 iterator객체를 통해 사용할 수 있다.
|
1 2 3 4 5 6 |
Set<String> setExample = new...; Iterator<String> iterator = setExample.iterator();
while(iterator.hasNext()){ String getin = iterator.next(); } |
cs |
보통 위 같은 방식으로, iterator 인터페이스에 선언된 hasNext()와 next() 메소드를 사용하여 구현한다.
Set 인터페이스를 구현한 주요 클래스는 3개가 있다.
|
Class |
특징 |
|
HashSet |
순서가 필요없는 데이터를 hash table에 저장. Set 중에 가장 성능이 좋음. |
|
TreeSet |
저장된 데이터의 값에 따라 정렬됨. red-black tree 타입으로 값이 저장됨. HashSet보다 성능이 느림. |
|
LinkedHashSet |
연결된 목록 타입으로 구현된 hash table에 데이터 저장. 저장된 순서에 따라 값이 정렬되나 셋 중 가장 느림 |
3개의 클래스의 성능 차이는 클래스 때문인데, 셋 중 HashSet이 특히 큰 dataset에서, 별도의 정렬작업이 없기 때문에 가장 빠르다. 또한 JDK 1.2부터 제공된 HashSet 클래스는 해시 알고리즘을 사용하였기 때문에 매우 빠른 검색 속도를 가진다.
이제 Set인터페이스를 구현한 HashSet에 대해서 좀 더 자세히 살펴보자.
HashSet
HashSet에 대한 코드를 살피기 전에 이 클래스에서 사용하는 해시 알고리즘에 대해 잠깐 설명해보겠다.
해시 알고리즘 : hash algorithm
해시 알고리즘이란 해시 함수(hash function)를 사용하여 데이터를 해시 테이블에 저장하고, 다시 그것을 검색하는 알고리즘이다.
그림과 함께 아주 간단히 설명하겠다.

자바에서 해시 알고리즘을 이용한 자료구조는 위의 그림과 같이 배열과 연결 리스트로 구현된다.
저장할 key값과 value를 넣으면 해시함수는 int index = key.hashCode() % capacity 연산으로 배열의 인덱스를 구하여 해당 인덱스에 저장된 연결 리스트에 데이터를 저장하게 된다.
예를 들어, key = 16이라면, hashCode() 메소드가 해당하는 int값을 그대로 반환하며, 16크기의 배열이 존재하므로 이 key의 인덱스는 16%16 = 0 이 된다. 따라서 첫번째 요소에 연결된 연결 리스트에서 검색을 시작한다.
다시 본론으로 돌아와서, HashSet의 기본 생성자는 다음과 같다.
|
Set<E> set = new HashSet<E>(); |
HashSet에서는 순서 없이, 동일한 객체의 중복 저장 없이 저장을 수행한다는 점을 언급했다. 따라서 add() 메소드를 사용하여 해당 HashSet에 이미 존재하고 있는 요소를 추가하려하면, 해당하는 요소를 바로 저장하지 않고 내부적으로 객체의 hashCode()메소드와 equals() 메소드를 호출하며 검사한다.
이 때 사용하는 hashCode()와 equals() 코드는 자신이 정의한 클래스 인스턴스에 대해 프로그래머가 직접 오버라이딩하여 구현할 수 있는데, 그 흐름을 이해하기 위해 먼저 String 클래스에서 오버라이딩된 두 메소드의 정의를 짚어보자.
문자열을 HashSet에 저장할 경우, 같은 문자열을 갖는 String 객체는 동등한 객체로, 다른 문자열을 갖는 String 객체는 다른 객체로 간주된다. 그 이유는 String 클래스가 hashCode()와 equals()메소드를 오버라이딩하여, 같은 문자열일 경우 hashCode()의 리턴값을 같게, equals()의 리턴값은 treu로 나오도록 구현해놓았기 때문이다.
Map : 인터페이스
Map 컬렉션에는 키(key)와 값(value)으로 구성된 Entry 객체를 저장하는 구조를 가지고 있다. 여기서 키와 값은 모두 객체이다.
값은 중복 저장이 가능하지만, 키는 중복 저장이 불가능하다. Set과 마찬가지로, Map 컬렉션에서는 키 값의 중복 저장이 허용되지 않는 데, 만약 중복 저장 시 먼저 저장된 값은 저장되지 않은 상태가 된다. 즉, 기존 값은 없어지고 새로운 값으로 대체되는 것이다.
HashSet에서처럼, 프로그래머는 HashMap과 HashTable 모두 키로 사용할 객체에 대해 hashCode()와 equals() 메소드를 오버라이딩하여 같은 객체가 될 조건을 정의할 수 있다.
HashMap
HashMap은 Map 인터페이스 구현을 위해 해시테이블을 사용한 클래스이다. 또한 중복을 허용하지 않고 순서를 보장하지 않는다.
중요한 점은, HashTable과 다르게 HashMap은 키와 값으로 null값이 허용된다는 것이다.
다음은 HashMap의 생성자를 전형화하여 나타낸것이다.
|
Map<K,V> map = new HashMap<K,V>(); |
HashMap에 대한 이론적인 설명은 여기까지하고 아래 코드로 설명을 덧붙이겠다.
아래 예시는 자바 명품 프로그래밍 7장에 있는 Open Challenging문제를 풀이한 것이다.
제네릭 해시맵(HashMap)을 이용하여 전화번호 관리 프로그램을 만들었다. Phone클래스는 전화번호 정보를 표현한 필드를 담은 클래스로, value에 해당한다. 따라서 value는 Phone 타입으로 들어갈 것이고, key값은 name 필드가 되겠다.
이 코드에서는 HashMap에서 사용하는 주요 메소드를 대부분 담고있으므로 이 코드만으로 충분한 공부가 될 것이라 본다.
import java.util.*;
class Phone{
private String name;
private String address;
private String telephone;
Phone(String name, String address, String telephone){
this.name = name;
this.address= address;
this.telephone = telephone;
}
public String getName(){ return name; }
public String getAddress(){ return address; }
public String getTelephone(){ return telephone; }
}
public class TelManagement {
//삽입
public static void insert(HashMap<String, Phone> map){
Phone p;
String name, address, telephone;
Scanner s = new Scanner(System.in);
System.out.print("이름 >> ");
name = s.next();
System.out.print("주소 >> ");
address = s.next();
System.out.print("전화번호 >> ");
telephone = s.next();
p = new Phone(name, address, telephone);
map.put(p.getName(), p);
}
//삭제
public static void delete(HashMap<String, Phone> map){
String deletename;
Scanner s = new Scanner(System.in);
System.out.print("이름>> ");
deletename = s.next();
if(map.containsKey(deletename)){
map.remove(deletename);
System.out.println("삭제가 정상적으로 완료되었습니다.");
}
else System.out.println(deletename + "은 등록되지 않은 사람입니다.");
}
//찾기
public static void search(HashMap<String, Phone> map){
Scanner s = new Scanner(System.in);
String searchname;
System.out.print("이름 >> ");
searchname = s.next();
if(map.containsKey(searchname))
System.out.println(searchname + " " + map.get(searchname).getAddress() + " "
+ map.get(searchname).getTelephone());
else System.out.println(searchname + "은 등록되지 않은 사람입니다. ");
}
//전체보기
public static void printall(HashMap<String, Phone> map){
Set<String> names = map.keySet();
Iterator<String> it = names.iterator();
while(it.hasNext()){
String name = it.next();
Phone student = map.get(name);
System.out.println(name + " " + student.getAddress() + " " + student.getTelephone());
}
}
//main
public static void main(String[] args){
int menu;
HashMap<String, Phone> map = new HashMap<String, Phone>();
Scanner s = new Scanner(System.in);
System.out.println("----------------------------------------------------");
System.out.println(" 전화번호 관리 프로그램을 시작합니다. ");
System.out.println("----------------------------------------------------");
while(true){
System.out.print("삽입:0, 삭제:1, 찾기:2, 전체보기:3, 종료:4 >> ");
menu = s.nextInt();
switch(menu){
case 0:
insert(map);
break;
case 1:
delete(map);
break;
case 2:
search(map);
break;
case 3:
printall(map);
break;
case 4:
System.out.println("프로그램을 종료합니다.");
return;
default:
System.out.println("잘못 입력하셨습니다. 다시 입력해주세요.");
}
}
}
}HashMap을 포함한 Map 컬렉션에서 Key값을 알고 싶다면 get() 메소드로 쉽게 구현하여 알아 낼 수 있다. 하지만 맵 안에 존재하는, value를 포함한 데이터 하나하나를 전부 얻어내 출력하고 싶다면, 그 방법은 2가지가 있다.
첫번째는, 위의 코드에서 구현한대로이다. 66번째 줄부터 구현한 코드인데, Key를 Set 타입으로 뽑아서 그 Key들을 하나하나 iterator 시켜, 그 Key 값을 통해 value를 얻어내는 방법이다. 이 코드는 이미 많은 책에 소개되어 있으므로 자세한 설명은 하지 않겠다.
두번째 방법은 entrySet을 통해 Entry 객체를 Set 타입으로 뽑아, Key와 value를 동시에 한번에 얻어낼 수 있는 방법이다. 즉, 위의 코드를 이렇게 바꾸어도 프로그램은 똑같이 문제없이 돌아간다.
public static void printall(HashMap<String, Phone> map){
Set<Map.Entry<String, Phone>> entries = map.entrySet();
Iterator<Map.Entry<String, Phone>> it = entries.iterator();
while(it.hasNext()){
Map.Entry<String, Phone> mapEntry = it.next();
System.out.println(mapEntry.getKey() + " " + mapEntry.getValue().getAddress() + " " + mapEntry.getValue().getTelephone());
}
}위의 코드는 DTO를 활용한 데이터 처리 방식을 채택하였다. 일반적으로 대량 데이터를 효율적으로 관리하기 위해 DTO(Data Transfer Object) 클래스와 컬렉션 API를 함께 사용하는 데, DTO는 이 때 데이터의 교환을 위한 객체를 의미한다. 즉, Phone 클래스는 DTO 클래스로 설계되었다 할 수 있다.
위 프로그램의 출력은 다음과 같다. 코드와 함께 보면 해시맵을 이해하는 데에 지장이 없을 것이다.
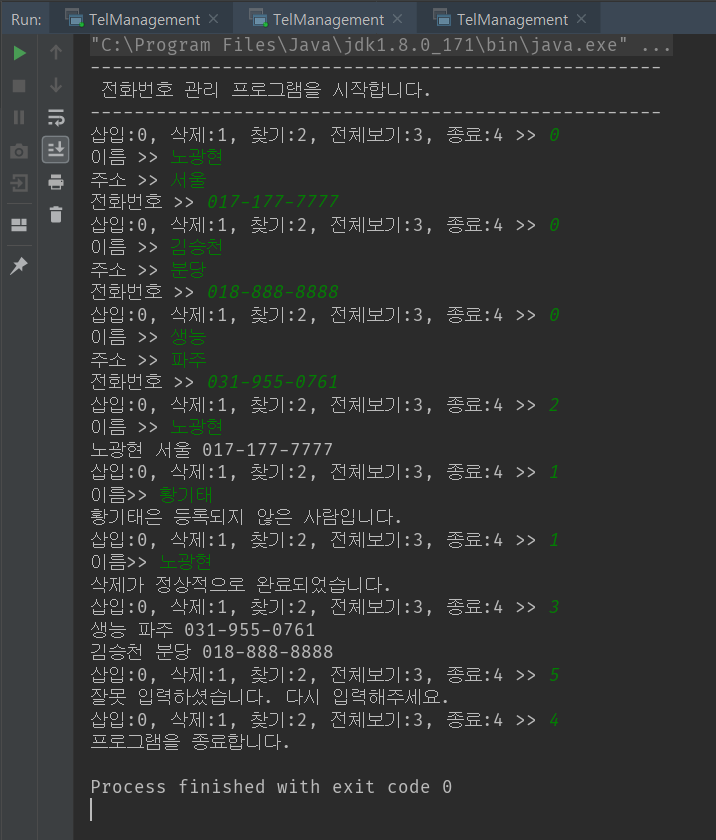
출처 : https://joooootopia.tistory.com/13
'Back-end > JAVA & Spring' 카테고리의 다른 글
| [log4j] 설정 및 사용방법 (0) | 2021.03.24 |
|---|---|
| [log4j ] Log4j 란 (0) | 2021.03.24 |
| [Spring] 스프링(Spring) 정의 및 특징 정리 (0) | 2021.03.14 |
| [Java] 메모리 릭 / 메모리 누수(Memory Leak) 현상 (0) | 2021.03.13 |
| JAVA 면접 용어 정리 (0) | 2021.03.12 |



댓글