이번 포스팅에서는 GAN의 개념, GAN의 종류, 주요 논문들에 대한 짧은 리뷰를 이야기하려고 합니다. GAN의 종류들은 중요하게 언급되는 모델들을 선정하였고, 이 모델들에 대해서 간단히 설명을 듣고 활용하실 수 있도록 리뷰도 같이 준비해보았습니다.
출처 :
ysbsb.github.io/gan/2020/06/17/GAN-newbie-guide.html
딥러닝 GAN 튜토리얼 - 시작부터 최신 트렌드까지 GAN 논문 순서 | mocha's machine learning
이번 포스팅에서는 GAN의 개념, GAN의 종류, 주요 논문들에 대한 짧은 리뷰를 이야기하려고 합니다. GAN의 종류들은 중요하게 언급되는 모델들을 선정하였고, 이 모델들에 대해서 간단히 설명을 듣
ysbsb.github.io
GAN이란?
GAN (Generative Adversarial Network)은 딥러닝 모델 중 이미지 생성에 널리 쓰이는 모델입니다. 기본적인 딥러닝 모델인 CNN (Convolutional Neural Network)은 이미지에서 개인지 고양이인지 구분하는 이미지 분류 (image classification) 문제에 널리 쓰입니다. GAN은 CNN과 달리 개는 라벨 0이 하고, 고양이는 라벨 1이라하는 것 처럼 진행하는 이미지 분류 문제보다 더 복잡합니다. GAN 모델이 데이터셋과 유사한 이미지를 만들도록 하는 것 입니다.
GAN은 현재 딥러닝계의 유명한 대가가 되신 Ian Goodfellow님이 2014년도 논문으로 아이디어를 발표했습니다. 이미지를 생성하는 원리를 “경찰과 위조지폐범”으로 비유하여 설명합니다. 위조지폐범은 위조지폐를 진짜 지폐와 거의 비슷하게 만듭니다. 위조지폐를 진짜 지폐로 속이고 사용할 수 있도록 말이죠. 경찰은 이 지폐가 진짜 지폐인지 위조지폐인지 구분하려 합니다. 위조지폐범과 경찰은 적대적인 관계에 있고, 위조지폐범은 계속 위조지폐를 생성하고 경찰은 진짜를 찾아내려고 하는 쫓고 쫓기는 과정이 반복되죠! 이 부분을 위조지폐범(Generator)와 경찰(Discriminator)가 서로 위조지폐를 생성하고 구분하는 것을 반복하는 minmax game이라 할 수 있습니다.
GAN은 Generator (생성자)와 Discriminator (판별자) 두 개의 모델이 동시에 적대적인 과정으로 학습합니다. 생성자 G는 실제 데이터 분포를 학습하고, 판별자 D는 원래의 데이터인지 생성자로부터 생성이 된 것인지 구분합니다. 생성자 G의 학습 과정은 이미지를 잘 생성해서 속일 확률을 높이고 판별자 D가 제대로 구분하는 확률을 높이는 두 플레이어의 minmax game의 과정이라고 볼 수 있습니다.

Ref: https://dreamgonfly.github.io/2018/03/17/gan-explained.html

모델 그림은 설명을 위해 제가 직접 그려보았습니다 :)
GAN 종류 정리
주요한 GAN 모델들을을 선정하고 종류별로 직접 도식화 해보았습니다. 저도 처음에 GAN을 공부할 때 이곳저곳 찾아보았던 기억이 있습니다. 처음 보시는 분들도 GAN이 어떤 종류들이 있고 어떻게 발전했는지 쉽게 파악하실 수 있도록 정리 해보았습니다.
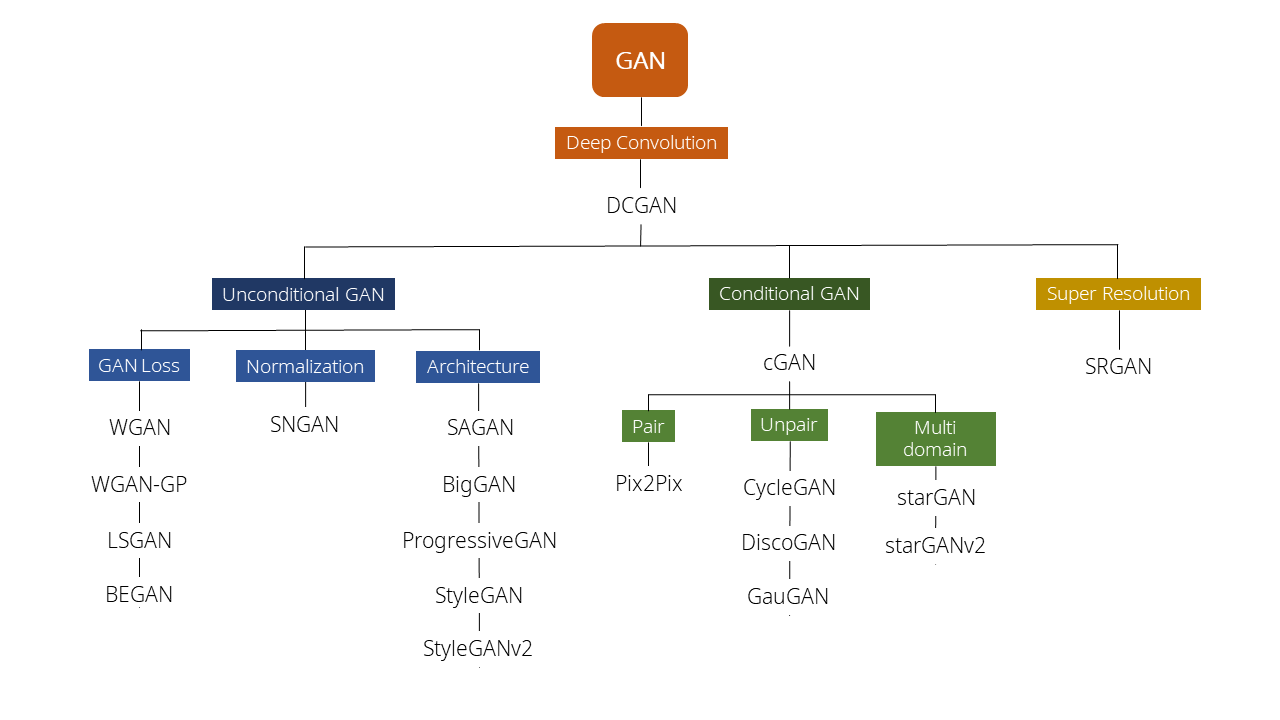
제가 직접 정리하여 도식화 해보았습니다.
GAN 논문 소개
위에서 소개한 GAN 모델들에 대해서 논문과 그에 대한 짧은 리뷰도 같이 이야기하려고 합니다. 간단한 설명을 같이 들었을 때 어떤 종류의 GAN이고 어떻게 활용하실지 생각하실 수 있고, 추가로 검색해보실 때에도 편하실거라 생각해서 소개해보려 합니다. 논문 소개는 간결한 문장으로 표현하도록 하겠습니다.
1. Generative Adversarial Nets [NIPS 2015]
- Ian Goodfellow가 최초로 GAN (Generative Adversarial Nets)를 제안한 논문. 새로운 이미지를 생성하는 생성자 Generator와 샘플 데이터와 생성자가 생성한 이미지를 구분하는 구별자 Discriminator 두 개의 네트워크 구조를 제안함. 생성자는 구별자를 속이면서 이미지를 잘 생성하려고 하며, 구별자는 주어진 이미지자 진짜인지 가까인지 판별함.


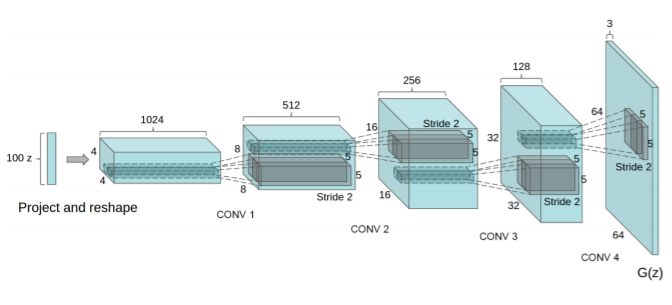
2. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks [ICLR 2016]
- 기존의 GAN에 CNN의 네트워크를 도입한 DCGAN (Deep Convolutonal Generative Adversarial Networks)를 제안함. Supervised learning에서 CNN이 큰 역할을 하고 있는데, unsupervised learning에서는 CNN이 주목을 덜 받고 있었음. 이렇게 CNN에서 성공적인 점을 GAN에도 적용하여 기존 GAN보다 훨씬 좋은 성능을 내게 되었음. 그 전까지 GAN만 사용하면 성능이 좋지 않았으나, DCGAN 이후로부터 GAN의 발전이 많이 되었음.

3. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets [NIPS 2016]
- InfoGAN (information-theoretic extension to the Generative Adversarial Network)을 제안함. Latent variable과 observation의 작은 부분 집합들 사이의 mutual information을 최대화시킴. Mutual information objective의 lower bound를 통해 효율적으로 최적화되로록 함.

4. WassersteinGAN
- 기존 GAN에서는 두 분포의 확률적 비교를 위해서 KL Divergence라는 식을 사용함. WGAN은 Wassestein Distance (EM distance)를 도입하여 다른 distance와 비교하여 어떤 성질을 가지는지 이론적으로 증명함. Discriminator의 함수가 Lipschitz constraint를 만족하게 하여, 결과적으로 gradient가 더 안정적으로 수렴하게 하였음.


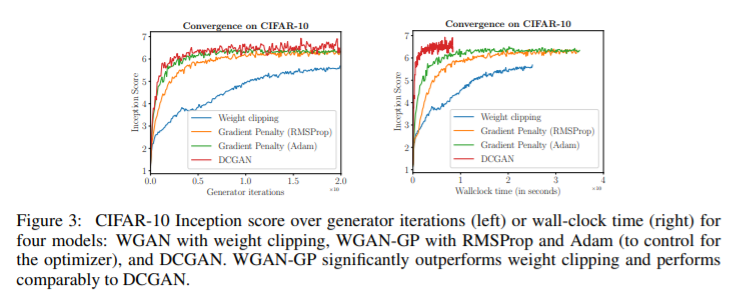
5. Improved Training of Wasserstein GANs [NIPS 2017]
- GAN은 학습 불안정성에 시달림. WassersteinGAN (WGAN)은 GAN의 안정적인 학습을 하기 위한 단계로 더 넘어갔으나, 때때로 안 좋은 샘플을 생성하거나 수렴에 실패할 경우가 있음. 이러한 문제들은 WGAN에서 critic (Discriminator)에 Lipschitz constraint를 부여하기 위해 weight clipping을 사용하는 것 때문임. Weight clipping을 대체하여 input에 대해 critic의 gradient norm을 부과하는 방법을 제안함. WGAN보다 성능이 좋고 학습이 안정적임.
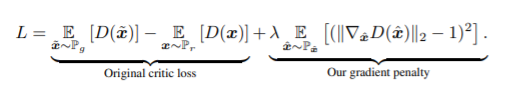

6. Least Squares Generative Adversarial Networks [ICCV 2017]
- 기존의 GAN은 sigmoid cross entropy loss function을 가진 discriminator를 classifier로써 가설을 세움 하지만, 이 loss function은 학습 과정 동안 vanishing gradient 문제로 이끌 수 있음. 이러한 문제를 극복하기 위해서, discriminator에 least square loss를 적용한 Least Squares Generative Adversarial Networks (LS-GANs)을 제한함. LSGAN의 목적함수를 최소화시키는 것은 Pearson divergence를 최소화시키도록 함. LSGAN은 기존 GAN 보다 성능이 좋고 안정적으로 학습이 가능함.


7. Energy-based Generative Adversarial Network
- Discriminator를 data manifold 근처 지역에는 낮은 에너지, 다른 지역에는 높은 에너지를 부과하는 energy function으로써 보는, Energy-based Generative Adversarial Network를 제안함. Generator는 최소한의 에너지를 사용해서 대조적인 이미지를 생성하도록 학습이 되고, discriminator는 이렇게 생성된 샘플들에 대해 높은 에너지를 부과하도록 학습되도록 봄. Discriminator를 energy function으로써 보는 입장은 logistic output이 나오는 binary classifier 뿐만 아니라 다양한 아키텍쳐와 loss function을 사용할 수 있도록 해줌. Auto-Encoder 구조를 사용하였고, energy는 reconstruction error로 볼 수 있음. EBGAN은 기존 GAN보다 학습 과정에서 더 안정적이며, 더 고화질의 이미지를 생성할 수 있음.
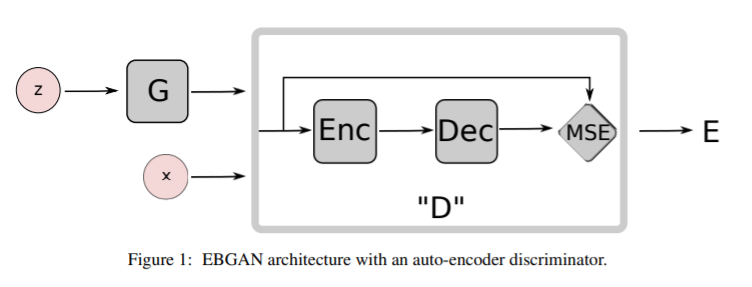
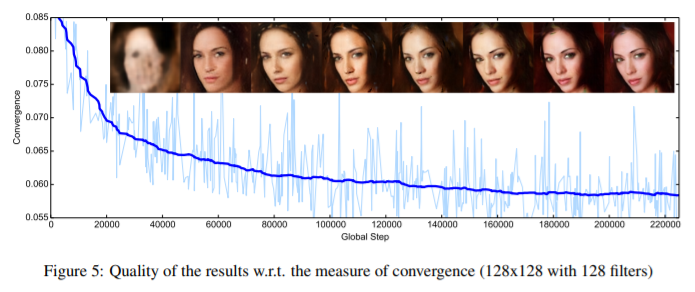
8. BEGAN: Boundary Equilibrium Generative Adversarial Networks
- Generator와 discriminator를 학습 과정동안 밸런스 시키는 방법을 제안함. 이 방법은 새로운 대략적인 수렴 측정 방법, 빠르고 안정적인 학습, 더 좋은 이미지 품질을 보여줌. 이미지 다양성와 시각적 품질 사이의 trade-off를 조절하는 방법을 유도함.
9. Conditional Generative Adversarial Nets
- Generative model의 conditional 버전을 제안함. 기존의 GAN이 입력으로 x data만 주었다면, 입력 data로 y도 추가하여 넣어서 generator와 discriminator 모두에 condition을 줄 수 있음.

10. Image-to-Image Translation with Conditional Adversarial Networks (Pix2Pix) [CVPR 2017]
- 입력 이미지와 출력 이미지를 맵핑하는 것을 학습할 뿐만 아니라, 이 맵핑을 train 하기 위한 loss function도 학습을 함. CNN에서 사용하는 Euclidean distance를 사용하면 blurry한 결과가 생성됨. Euclidean distance는 모든 그럴듯한 결과들의 평균을 최소화하기 때문. “실제와 구분하기 어려운 결과를 만들기”라는 high-level 목표에 특정해서 생각하면, 이러한 목표에 만족하는 적절한 loss function을 학습하면 됨. 최근에 GAN의 적절한 loss function을 찾기 위한 연구들이 많았고, L2 distance를 많이 사용함. L1 distance를 사용함. L1 distance를 사용하는 것이 L2 distance를 사용하는 것 보다 blurring이 덜 함.

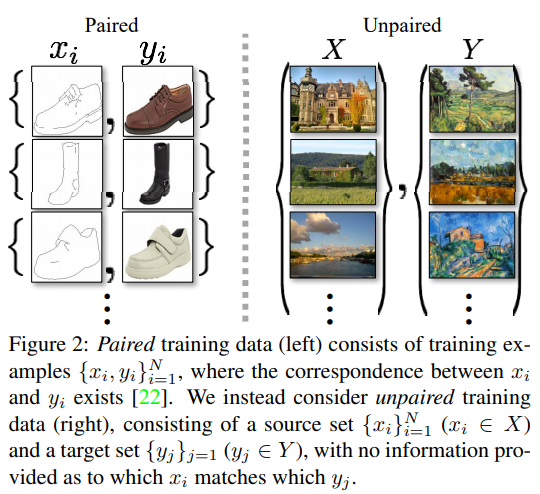
11. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks (CycleGAN) [ICCV 2017]
- Image-to-Image translation 방법으로 source domain X로부터 target domain Y로 맵핑하는 함수 G: X→Y와 이에 대한 inverse mapping 함수 F: Y→X를 학습함. cycle consistency loss는 source domain X의 이미지 x가 함수 G를 거쳐 target domain으로 변형되고 이 이미지가 다시 함수 F를 거쳐서 source domain의 이미지 x로 잘 돌아오는지를 반영함. 이의 반대 과정 y의 이미지가 함수 F를 거치고 함수 G를 거치고 나서 다시 y로 잘 돌아오는지도 포함되어 있음. 결과적으로 CycleGAN은 X domain과 Y domain이 unpaired 되어 있더라도 mapping하는 함수를 학습함으로써 unpaired image translation을 할 수 있음.

12. Semantic Image Synthesis with Spatially-Adaptive Normalization (SPADE, GauGAN) [CVPR 2019]
- 입력 semantic layout이 주어졌을 때 photorealistic Spatially-adaptive normalization을 제안함. 이전의 방법들은 convolution, normalization, nonlinearity layer로 구성되어 있는 네트워크에 semantic layout을 바로 넣었음. 이 경우 normalization 레이어가 시맨틱 정보를 소실시키는 경향이 있다는 것을 보임. 이런 문제를 해결하기 위해, spatially-adaptive와 learened trainsformationd을 통해서normalization 레이어들 안의 activation을 조정하기 위한 입력 레이아웃을 사용함. 결과적으로 SPADE는 시맨틱과 스타일을 모두 컨트롤 할 수 있음.


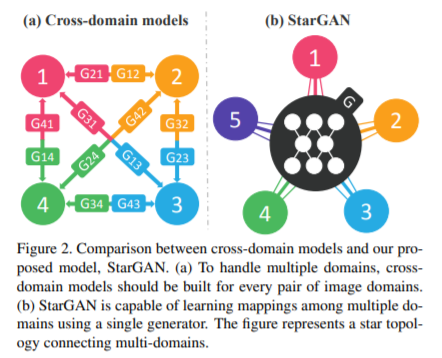
13. StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation [CVPR 2018]
기존의 연구들에서 두 개의 도메인의 image-to-image translation의 성공을 보여줌. 하지만, 기존의 접근법들은 두 개 이상의 도메인에 대해 다루기 어렵고, 모든 이미지 도메인의 짝마다 독립적으로 다른 모델들을 생성해야 함. StarGAN은 이런 한계를 극복하고, 오직 하나의 모델만 가지고 다양한 데이터셋에서 다양한 도메인을 위한 image-to-image translation을 수행할 수 있음.

14. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
- 기존 이미지 Super-Resolution 문제에서 정확도와 스피드 측면에서 많은 발전을 이루었지만, 질감의 디테일을 어떻게 회복시킬 것인지에 대한 문제가 있었음. Loss로 MSE loss를 사용하는데 PSNR ratio는 높지만 고해상도에서 high-frequency detail이 떨어짐. SRGAN은 이러한 문제를 해결하기 위한 Super Resolution 문제에 대한 GAN 네트워크를 처음 제시함. adversarial loss와 content loss로 구성되어 있는 perceptual loss를 사용함.


15. Spectral Normalization for Generative Adversarial Networks (SNGAN) [ICLR 2018]
- GAN 학습의 불안정성은 GAN의 큰 문제 중 하나임. SNGAN은 Discriminator의 학습을 안정화시키는 방법으로 spectral normalization이라는 방법을 제안함. WGAN에서는 discriminator의 함수가 Lipschitz constraint를 만족시키도록 하는데, 이를 대체아여 spectral normalization으로 바꾸어 적용하여 기존의 normalization 방법보다 계산이 효율적이며 학습을 안정화시킴.

16. Self-Attention Generative Adversarial Networks
- GAN의 Self-Attention 개념과 이전 연구에서 제안되었던 Spectral Normalization을 도입함. 기존의 convolution GAN은 오직 저해상도의 feature map안에서 지역적 정보만을 가지고 고해상도의 디테일을 생성함. SAGAN은 모든 feature location으로부터 단서들을 가져와서 이미지를 생성함. Discriminator는 더 디데일한 feature로 이미지 안에서 먼 지역간의 연속성을 확인할 수 있음. Spectral Normalization을 도입하여 학습을 더 안정적이도록 보완함.
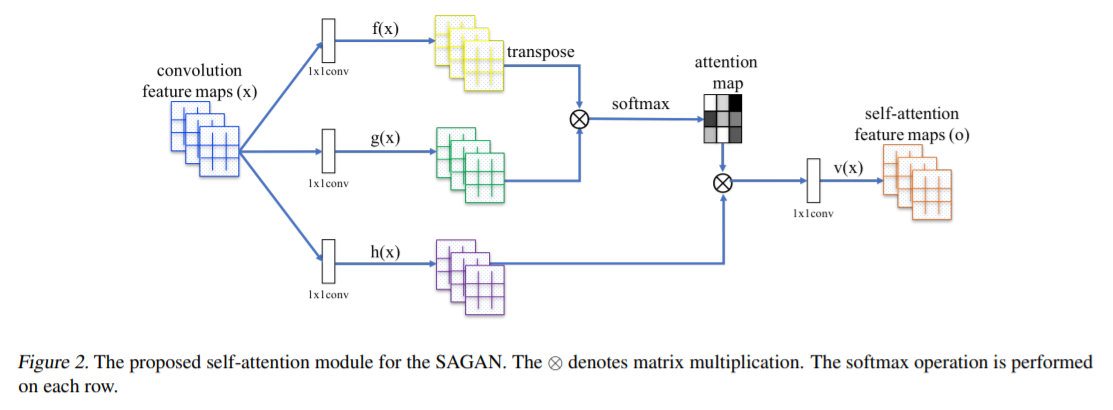

17. Large Scale GAN Training for High Fidelity Natural Image Synthesis (BigGAN) [ICLR 2019]
- GAN에서 고해상도 이미지를 생성하는 것이 성공적이었으나, ImageNet과 같이 복잡한 데이터셋에서 오는 다양한 샘플들로부터 학습하는 것은 아직 남아있는 문제였음. BigGAN은 large scale에 대해서도 학습하도록 함. Generator에 orthogonal regularization을 적용하는 것은 간단한 truncation trick을 사용할 수 있도록 하고, fidelity와 variety 간의 trade-off를 control 할 수 있도록 함. 이전 GAN의 SOTA 성능은 IS가 52.52이고 FID가 18.65였다면, BigGAN은 IS 166.5이고 FID는 7.4로 엄청난 성능 향상을 보였음. (IS: Inception Score는 높을 수록 좋고, FID: Fretchet Inception Distance는 낮을 수록 좋음.)

18. Progressive Growing of GANs for Improved Quality, Stability, and Variation (ProgressiveGAN) [ICLR 2018]
- Generator와 Discriminator를 점진적으로 학습하는 방법. 저해상도로부터 시작해서, 트레이닝 과정 동안 모델에 새로운 레이어를 추가하면서 디테일을 세밀화 하는 방법으로 학습 속도를 빠르게 하면서 안정화시킬 수 있음. 결과적으로 이전보터 훨씬 고해상도의 이미지를 생성할 수 있음.

19. A Style-Based Generator Architecture for Generative Adversarial Networks (StyleGAN) [CVPR 2019]
- Generator 네트워크에서 각 레이어마다 스타일 정보를 입히는 방식으로 학습함. 이미지의 스타일 (성별, 포즈. 머리색, 피부톤 등)을 변경할 수 있음. Latent vector z는 특정 데이터셋의 분포를 그대로 따라가는 경향이 있는데, 이를 보완하기 위해서 그대로 사용하는 것이 아니라 Mapping network를 만들어서 나온 w vector를 활용하여 스타일을 더 다양하게 바꿀 수 있도록 함.
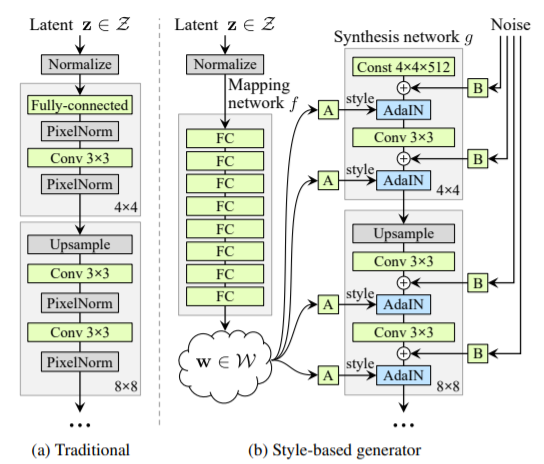

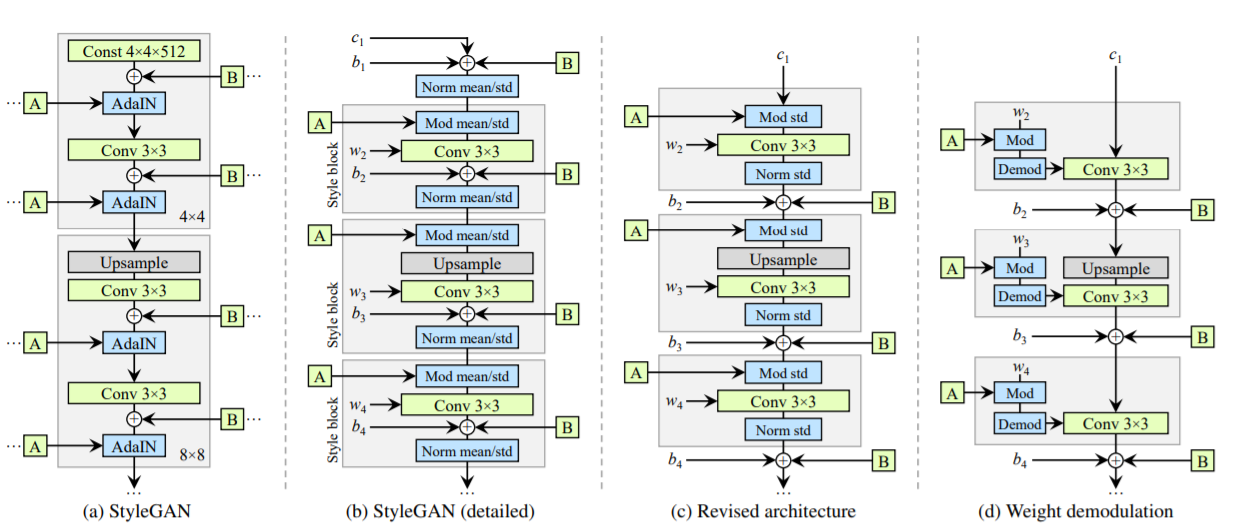
20. Analyzing and Improving the Image Quality of StyleGAN [StyleGANv2]
- Latent에서 이미지로 맵핑을 잘 하도록 normalization, regularization, progressivie growing 등을 포함하여 Generator를 재설계함. StyleGAN에서 이미지를 생성했을 때 원래의 이미지와 관련 없는 이상한 부분이 나오는 경우 (artifact)를 볼 수 있었음. 이의 원인을 latent space에서 mapping function을 통하는 AdaIN operation을 할 때 normalization이 문제가 있다고 분석하여 네트워크를 수정함.
여기까지 GAN의 개념과 종류들, 주요 논문에 대한 간단한 리뷰까지 설명을 해보았습니다.
'AI > 딥러닝' 카테고리의 다른 글
| ANN, DNN, CNN, RNN, GAN 이란? (1) | 2021.04.01 |
|---|---|
| 쉽게 씌어진 GAN (2) | 2021.04.01 |
| 딥러닝을 활용한 객체 탐지 알고리즘 이해하기 (2) | 2021.03.31 |
| 딥러닝의 종류와 개념 (0) | 2021.03.31 |
| 인공지능 학습 데이터 구축에 필요한 ‘데이터 라벨링’이란? (0) | 2021.03.26 |




댓글