오늘 날 괄목할 만한 인공지능 기술과 서비스의 출현은 딥러닝을 중심으로 한 기계학습 기술의 급속한 발전에서 기인한다.특히 많은 전문가들이 딥러닝 기술의 발전 요인으로 꼽는 것이 GPU 등의 하드웨어 발전, ArXiv, Github 등으로 대변되는 적극적인 기술 공유 문화를 통한 짧은 시간내 많은 전문가들의 등장, 그리고 방대한 양의 신경망 파라미터를 효과적으로 활용가능토록 하는 대규모 학습데이터 구축 및 공개 등이다. 본 고에서는 이 요소들 중 딥러닝 학습에 널리 그리고 유용하게 활용되고 있는 대규모 공개 데이터 특히 computer vision 기술 연구에 활용되고 있는 이미지 데이터 셋에 대하여 공유한다.
글. 하정우 (네이버 Clova AI Research)
1. 범용 대규모 이미지 데이터셋
2009년 공개된 이후로 ImageNet 데이터셋 [J. Deng et al. 2009] 은 최근까지 이미지 분류뿐 아니라 객체인식(object detection), 의미 분할(semantic segmentation), 자세 추정(pose estimation) 등의 다양한 컴퓨터 비전 문제에 활용될 수 있는 공통 convolutional neural network (CNN) 백본 모델 학습에 널리 활용되어 왔다. 최근에도 ImageNet-1k (1000 클래스 Image 데이터)는 이미지 분류 모델의 성능 평가를 위한 표준 평가데이터로 활용되고 있다. 그러나 최근에는 ImageNet 보다 더 큰 규모와 더 다양한 레이블 정보를 제공하는 여러 데이터가 공개되고 있다.
① OpenImage [R. Benenson et al. 2019]
2016년에 공개된 이후로 [I. Karison et al. 2016] 현재 V5까지 지속적으로 업데이트 되고 있는 현존 최대 규모 범용 이미지 데이터이다. V5+Extension 버전 기준으로 객체 바운딩 박스, 객체 분할 마스크, 시각 관계 정보 등 다양한 레이블 정보를 포함한 약 9천만장의 데이터셋이다.
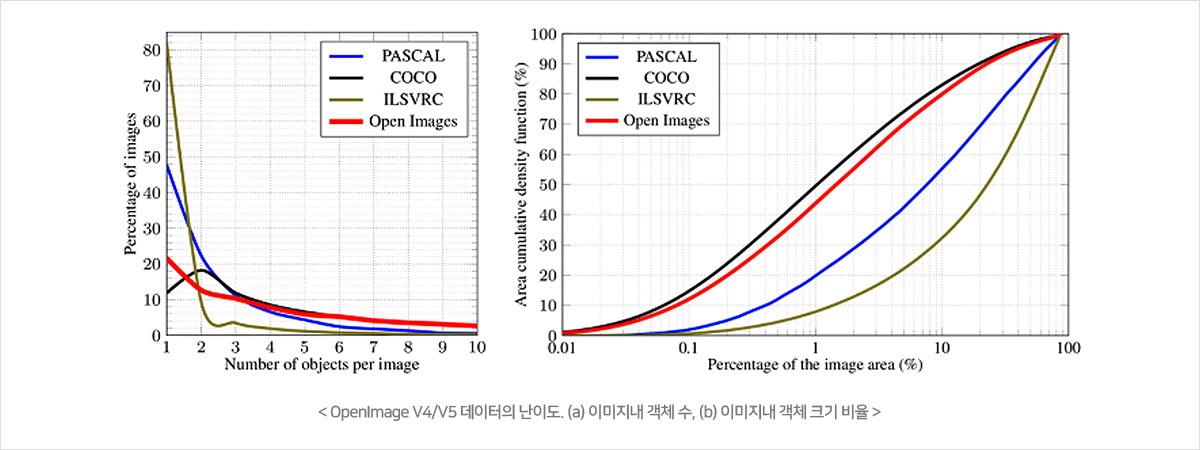
9천만장의 데이터셋이다. 특히 600개의 객체 종류를 포함하고 있는 190만개의 이미지에 대해 1600만개의 바운딩 박스 정보가 포함되어 있다. 그리고 그림 1에서와 같이 기존 유사 데이터 대비 물체의 크기의 편차도 훨씬 심하고 다양해서 학습시키기 더 어려운 데이터셋으로 인식되고 있다. 반대로 실제 세계의 데이터와 유사하고 지속적으로 데이터가 업데이트되고 있기 때문에 AI 스타트업이나 연구조직에서 활용하기 유용한 데이터로 인식되고 있다.
② Microsoft COCO [Tsung-Yi Lin et al. 2014]
이미지 캡셔닝과 Visual Question Answering (VQA) [S. Antol et al. 2015] 라면 가장 먼저 떠오르는 데이터 중 하나가 바로 MS COCO이다. VQA 1.0과 2.0 데이터셋이 MS COCO를 기반으로 해서 만들어졌고 이미지-텍스트 연구는 Flickr 데이터와 더불어 가장 널리 활용되는 데이터이다. 뿐만 아니라 최근 객체 인식 모델의 성능 평가에 있어서 가장 널리 활용되는 데이터도 바로 MS COCO 데이터 이다. 구체적으로 약 20만장의 이미지에서 전체 80종류 150만개 객체들에 대한 영역 분할 (instance segmentation) 정보가 포함되어 있다. 또한 각 이미지 마다 5개의 이미지를 설명하는 문장들을 포함하고 있다.

③ LVIS [Agrim Gupta et al. 2019]
지난 여름 Facebook research에서 MS COCO 2017 데이터를 활용하여 그림 3과 같이 훨씬 더 많은 종류의 객체에 대하여 영역 정보를 제공함으로써 데이터의 활용도를 더욱 향상시킨 데이터셋이다. 1200개 이상의 객체 종류에 대하여 약 2백만개 객체 영역 정보제공을 목표로 한다. 다른 데이터셋들과 마찬가지로 ICCV 2019 워크샵과 연계하여 챌린지를 개최한다. 훈련/검증/평가 데이터는 각각 약 5.7만장(70만 객체), 5천장 (5만 객체), 2만 장 이미지로 구성되어 있다.

2. 얼굴 데이터셋
얼굴 인식은 컴퓨터 비전 분야에서 가장 다양한 실제 서비스와 직결된 기술 중의 하나이다. 특히 중국을 중심으로 얼굴감지와 인식을 위해 다양한 데이터들이 공개되었다. 또한 최근 Generative adversarial network (GAN) [I. Goodfellow et al. 2014]의 발전에 따라 얼굴 생성 모델 학습을 위한 다양한 데이터들이 공개되었다. 얼굴 데이터는 대부분 초상권 이슈와 연관되어 있어 상업용 활용이 특히 다른 데이터 대비 극히 제한된다. 이에 최근에는 StyleGAN [T. Karras et al. 2019] 을 이용하여 가상으로 생성된 얼굴 이미지를 공개함으로써 초상권 문제를 회피하고 있다.
① Widerface [S. Yang et al. 2016]
Widerface 데이터셋은 2016년 CVPR학회를 통해 홍콩중문대학 (Chinese University of Hong Kong)에서 공개한 데이터로 실세계 얼굴 감지(face detection) 모델 평가 용도로 가장 널리 활용되고 있다 (그림4). 이 데이터는 얼굴의 크기에 따라 Easy, Medium, Hard로 구분되며 총 32000여장의 이미지에 39여만명의 얼굴의 바운딩 박스가 레이블 되어 있다.

② B. CelebA [Z. Liu et al 2015]
CelebA는 Widerface를 공개한 홍콩중문대학의 연구실에서 ICCV 2015를 통해 발표 한 데이터로 GAN을 이용한 얼굴 생성과 관련하여 가장 널리 사용되는 데이터셋이다. 1만명 이상의 전세계 셀럽들에 대해 20만장 이상의 이미지에 머리색, 헤어스타일, 장신구류 포함 40여가지 특징들의 정보가 태깅되어 있어 Image-to-image translation연구에 널리 사용된다. CelebA 이후 Nvidia에서 PrgressiveGAN [T. Karras et al. 2018]을 발표하면서 1024 X 1024 고해상도의 CelebA 데이터인 CelebAHQ를 함께 공개했다. 또한 StyleGAN 발표와 함께 기존의 Celeb들에 치중되었던 데이터 대신 7만장의 일반인들의 얼굴 사진인 Flickr-Face-HQ (FFHQ) 데이터셋을 공개했다. 이를 통해 훨씬 다양한 얼굴의 이미지 생성이 가능해졌다.

3. AI-Hub 데이터셋
과학기술정보통신부와 한국정보화진흥원(NIA) 에서는 지난 수년간 이미지, 텍스트, 법률, 농업, 영상, 음성 등 다양한 분야의 딥러닝 학습에 필요한 데이터를 수집 구축하고 이를 AI-Hub 를 통해 공개하고 있다. 이미지 데이터로는 한국인 안면 이미지, 질병 진단이미지, 한국형 사물 이미지. 손글씨 이미지 등을 공개하고 있다. 또한 내년에도 추가로 다양한 종류의 데이터를 추가 구축 공개 예정이다.
참고 문헌
- [J. Deng et al. 2009] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, Li Fei-Fei, Imagenet: A large-scale hierarchical image database, CVPR 2009.(http://image-net.org/index)
- [I. Karison et al. 2016] I. Karison et al. OpenImages: A public dataset for large-scale multi-label and multi-class image classification. 2016. https://github.com/openimages
- [R. Benenson et al. 2019] R. Benenson, S. Popov, and V. Ferrari. Large-scale interactive object segmentation with human annotators. CVPR 2019 [T.-Y. Lin et al. 2014] Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, Piotr Dollár. ECCV 2014.
- [S. Antol et al. 2015] S. Antol and Aishwarya Agrawal and Jiasen Lu and Margaret Mitchell and Dhruv Batra and C. Lawrence Zitnick and Devi Parikh. VQA: Visual Question Answering. ICCV 2015.
- [A. Gupta et al. 2019] Agrim Gupta, Piotr Dollár, Ross Girshick. LVIS: A Dataset for Large Vocabulary Instance Segmentation.
- [I. Goodfellow et al. 2014] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio. Generative Adversarial Nets. NIPS 2014.
- [T. Karras et al. 2019] Tero Karras, Samuli Laine, Timo Aila. A Style-Based Generator Architecture for Generative Adversarial Networks. CVPR 2019.
- [S. Yang et al. 2016] Shuo Yang, Ping Luo, Chen-Change Loy, Xiaoou Tang. WIDER FACE: A Face Detection Benchmark. CVPR 2016.
- [Z. Liu et al 2015] Ziwei Liu, Ping Luo, Xiaogang Wang, Xiaoou Tang. Deep Learning Face Attributes in the Wild. ICCV 2015.
- [T. Karras et al. 2018] Tero Karras, Timo Aila, Samuli Laine, Jaakko Lehtinen. Progressive Growing of GANs for Improved Quality, Stability, and Variation. ICLR 2018.
출처 : http://webzine.aihub.or.kr/insight/vol01/sub4.php
'AI > 딥러닝' 카테고리의 다른 글
| GAN의 종류 (0) | 2021.04.13 |
|---|---|
| S2FGAN 개인 공부 (0) | 2021.04.02 |
| 학습 모델의 종류 (0) | 2021.04.01 |
| ANN, DNN, CNN, RNN, GAN 이란? (1) | 2021.04.01 |
| 쉽게 씌어진 GAN (2) | 2021.04.01 |


댓글